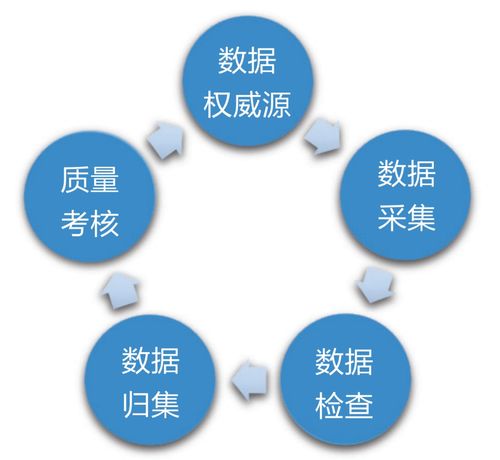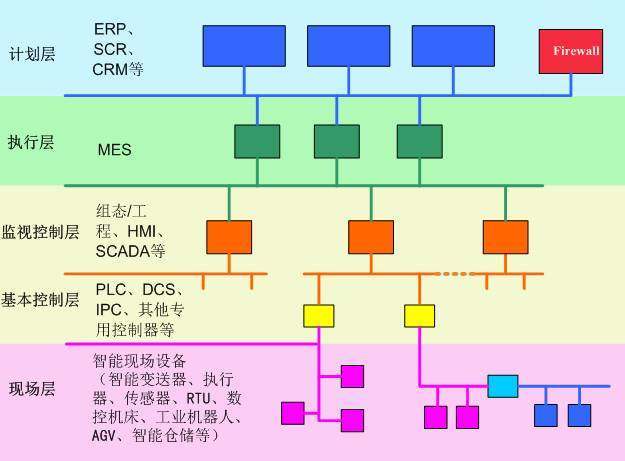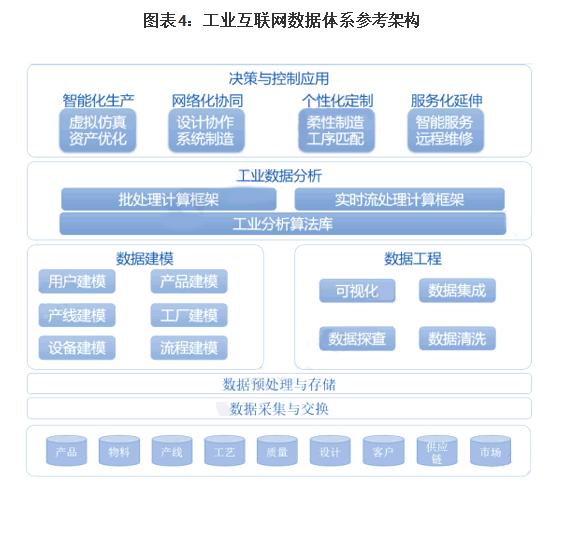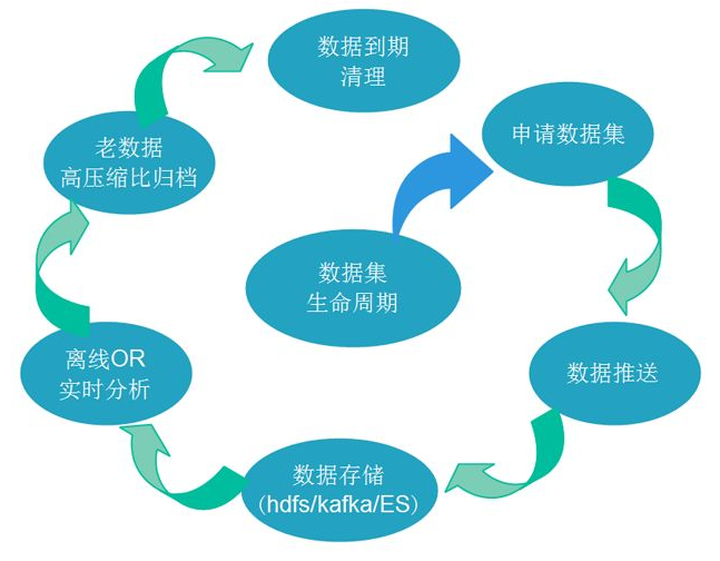
在大數(shù)據(jù)技術生態(tài)中,Apache Kafka 已從一個高性能的消息隊列系統(tǒng),演變?yōu)橐粋€核心的實時數(shù)據(jù)流平臺,扮演著“中樞神經(jīng)系統(tǒng)”或“數(shù)據(jù)總線”的關鍵角色。它專為處理高吞吐、低延遲的實時數(shù)據(jù)流而設計,有效連接了數(shù)據(jù)生產(chǎn)者與消費者,是現(xiàn)代數(shù)據(jù)管道和流處理應用不可或缺的組件。
一、 基本概念解析
- 分布式流處理平臺:Kafka 的核心定位。它不僅僅傳遞消息,更能持久化、存儲數(shù)據(jù)流,并支持在數(shù)據(jù)移動過程中進行實時處理。
- 發(fā)布/訂閱消息模型:數(shù)據(jù)生產(chǎn)者(Producer)將消息發(fā)布到特定的類別(稱為Topic),而數(shù)據(jù)消費者(Consumer)則訂閱這些Topic來接收和處理消息。生產(chǎn)者和消費者之間完全解耦。
- 日志(Log)數(shù)據(jù)結構:Kafka 的存儲核心。每個Topic下的數(shù)據(jù)被組織成一個僅追加(append-only)、按序排列的持久化日志序列。這種設計保證了極高的順序讀寫性能和數(shù)據(jù)可靠性。
- 實時數(shù)據(jù)管道:Kafka 常被用作連接不同數(shù)據(jù)系統(tǒng)(如業(yè)務數(shù)據(jù)庫、Hadoop、數(shù)據(jù)倉庫、實時計算引擎)的可靠管道,實現(xiàn)數(shù)據(jù)的實時流動。
二、 核心組件詳解
Kafka 架構主要由以下幾個核心組件構成,共同協(xié)作以提供高可用、可擴展的數(shù)據(jù)流服務:
- Producer(生產(chǎn)者):
- 角色:向Kafka集群中的特定Topic推送數(shù)據(jù)的客戶端應用程序。
- 關鍵行為:可以指定將消息發(fā)送到Topic的哪個分區(qū)(Partition),支持同步/異步發(fā)送,并可通過配置確認(ack)機制確保數(shù)據(jù)可靠送達。
- Consumer(消費者):
- 角色:從Topic拉取(pull)并處理數(shù)據(jù)的客戶端應用程序。
- 關鍵概念:消費者以消費者組(Consumer Group)的形式工作。組內(nèi)消費者共同消費一個Topic,每條消息在同一時刻只會被組內(nèi)的一個消費者處理,從而實現(xiàn)消費的并行擴展與負載均衡。
- Broker(代理服務器):
- 角色:Kafka集群中的單個服務節(jié)點,負責接收生產(chǎn)者的消息、分配偏移量(Offset)、持久化存儲數(shù)據(jù),并響應消費者的拉取請求。
- 集群化:一個Kafka集群由多個Broker組成,實現(xiàn)數(shù)據(jù)冗余、負載均衡和高可用性。
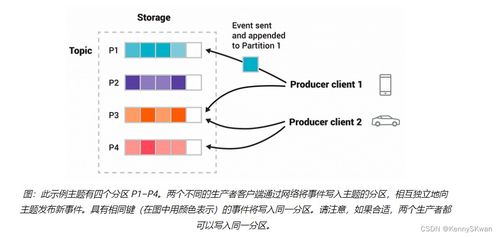
- Topic(主題)與 Partition(分區(qū)):
- Topic:數(shù)據(jù)記錄的類別或訂閱源名稱,是生產(chǎn)者與消費者交互的邏輯單元。
- Partition:Topic在物理上的細分。每個Topic可以被分為多個分區(qū),分布在不同Broker上。分區(qū)是Kafka實現(xiàn)水平擴展和并行處理的基礎。消息在分區(qū)內(nèi)嚴格有序,但跨分區(qū)不保證順序。
- ZooKeeper / KRaft(集群元數(shù)據(jù)管理與協(xié)調(diào)):
- 傳統(tǒng)角色(ZooKeeper):在Kafka 2.8版本之前,Kafka依賴ZooKeeper來管理集群元數(shù)據(jù)(如Broker、Topic、分區(qū)狀態(tài))、進行領導者選舉和維持消費者組偏移量。
- 演進(KRaft模式):自Kafka 3.0起,Kafka引入了基于Raft共識協(xié)議的KRaft模式,逐步取代ZooKeeper,將元數(shù)據(jù)管理內(nèi)置于Kafka自身,簡化了架構部署與運維。
- Connector與Streams(高級數(shù)據(jù)處理服務):
- Kafka Connect:一個用于在Kafka和其他系統(tǒng)(如數(shù)據(jù)庫、搜索引擎、文件系統(tǒng))之間進行可擴展、可靠數(shù)據(jù)導入導出的框架。它通過豐富的預構建連接器(Connector)簡化了數(shù)據(jù)集成任務。
- Kafka Streams:一個用于構建實時流處理應用程序的客戶端庫。開發(fā)者可以直接在業(yè)務應用中利用它進行復雜的事件處理、流聚合、窗口操作等,而無需部署額外的流處理集群。它讓Kafka從“數(shù)據(jù)管道”升級為完整的“流處理平臺”。
三、 作為數(shù)據(jù)處理服務的價值
在大數(shù)據(jù)體系中,Kafka提供的數(shù)據(jù)處理服務體現(xiàn)在:
- 解耦與緩沖:在數(shù)據(jù)生產(chǎn)者和消費者之間建立異步緩沖層,應對流量峰值,防止系統(tǒng)間耦合導致的級聯(lián)故障。
- 數(shù)據(jù)持久化與重播:消息可配置持久化存儲一段時間,允許消費者按需重播歷史數(shù)據(jù),為故障恢復、回溯分析和新應用上線提供便利。
- 流處理基礎:通過與Kafka Streams或第三方流處理引擎(如Flink、Spark Streaming)無縫集成,為實時監(jiān)控、實時風控、實時推薦等場景提供低延遲的數(shù)據(jù)處理能力。
- 數(shù)據(jù)集成樞紐:借助Kafka Connect,它成為統(tǒng)一的數(shù)據(jù)接入和分發(fā)中心,簡化了復雜數(shù)據(jù)架構的構建與管理。
###
Apache Kafka 以其獨特的日志存儲模型、分布式架構和豐富的生態(tài)組件,成功解決了大數(shù)據(jù)場景下實時數(shù)據(jù)流的可靠收集、存儲與分發(fā)問題。理解其Producer、Consumer、Broker、Topic/Partition等核心組件,以及Kafka Connect和Kafka Streams所延伸的數(shù)據(jù)處理服務能力,是構建高效、健壯實時數(shù)據(jù)管道的關鍵。它已然成為大數(shù)據(jù)技術棧中連接批處理與流處理、在線與離線系統(tǒng)的核心基礎設施。